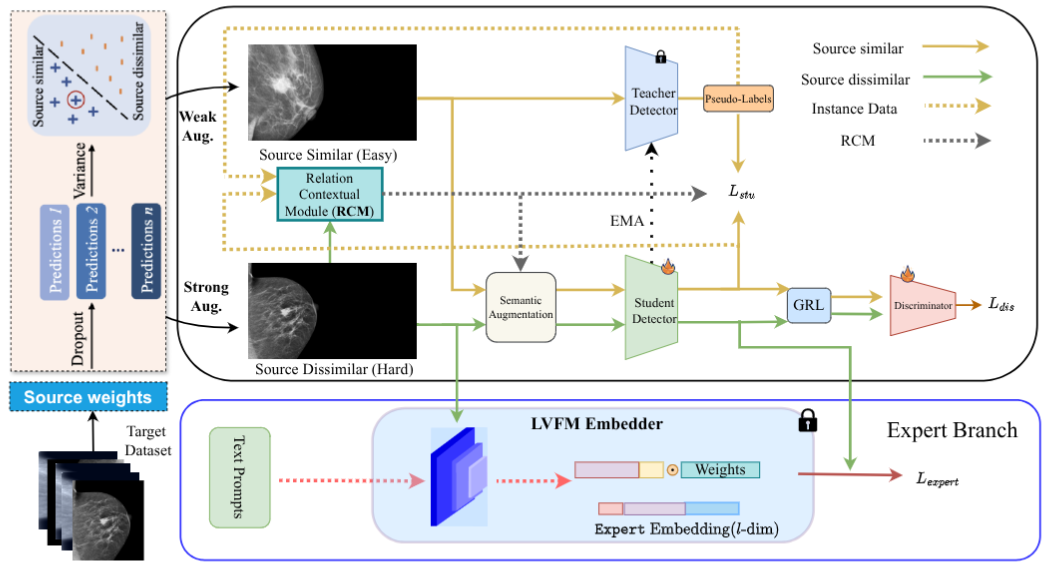
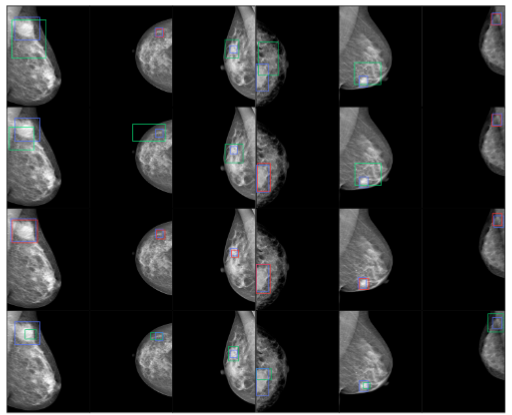
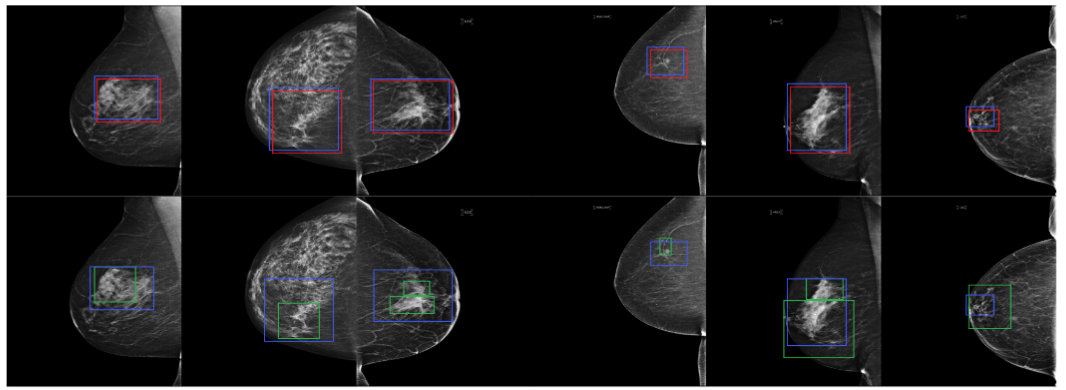
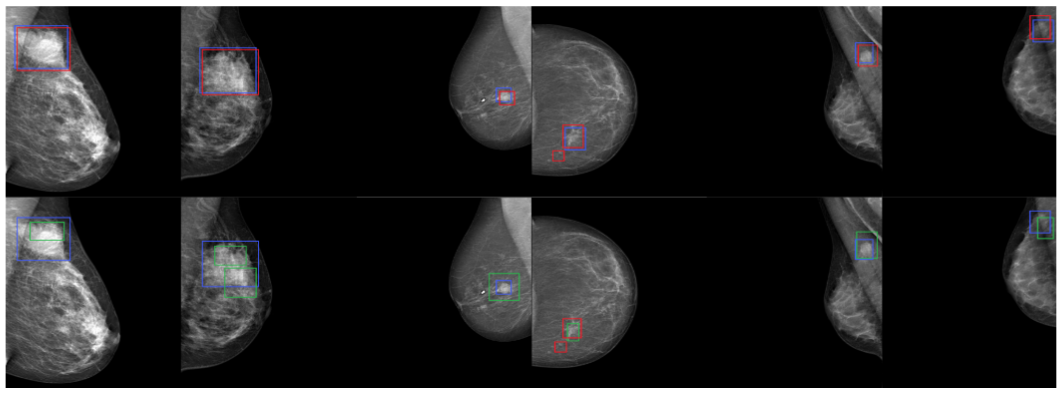
Framework Architecture
The GT framework consists of a student–teacher pair connected by EMA weight updates. The Relational Context Module sits between them, maintaining a running confusion matrix that guides both the Cropbank sampling strategy and the Semantic-Aware Loss.
A frozen Expert Branch (BioMedParse / GroundingDINO) provides an additional supervision signal to the student during training. At inference, only the student runs, the expert adds zero latency.
The variance-based domain splitter partitions target images into source-similar and source-dissimilar subsets, allowing tailored augmentation strength in each region.